Using machine learning to predict client churn
Built a PyTorch GRU-based churn model on advertiser-level time-series data to predict per-period churn risk (p_churn_gru), enabling earlier retention targeting than static snapshot models.
Engineered an end-to-end sequence pipeline (cadence normalization, feature inference, label joins, scaling, padded variable-length batching with masking) that supported monthly/weekly scoring and robust training on partially labeled data.
Delivered reproducible ML artifacts (trained weights, scaler metadata, training history, config, and scored outputs) to streamline deployment, monitoring, and future model iteration.
Implemented leakage-aware validation by splitting at the advertiser level and productionized model evaluation with AUC, average precision, and Brier score for discrimination + calibration tracking.
Overview
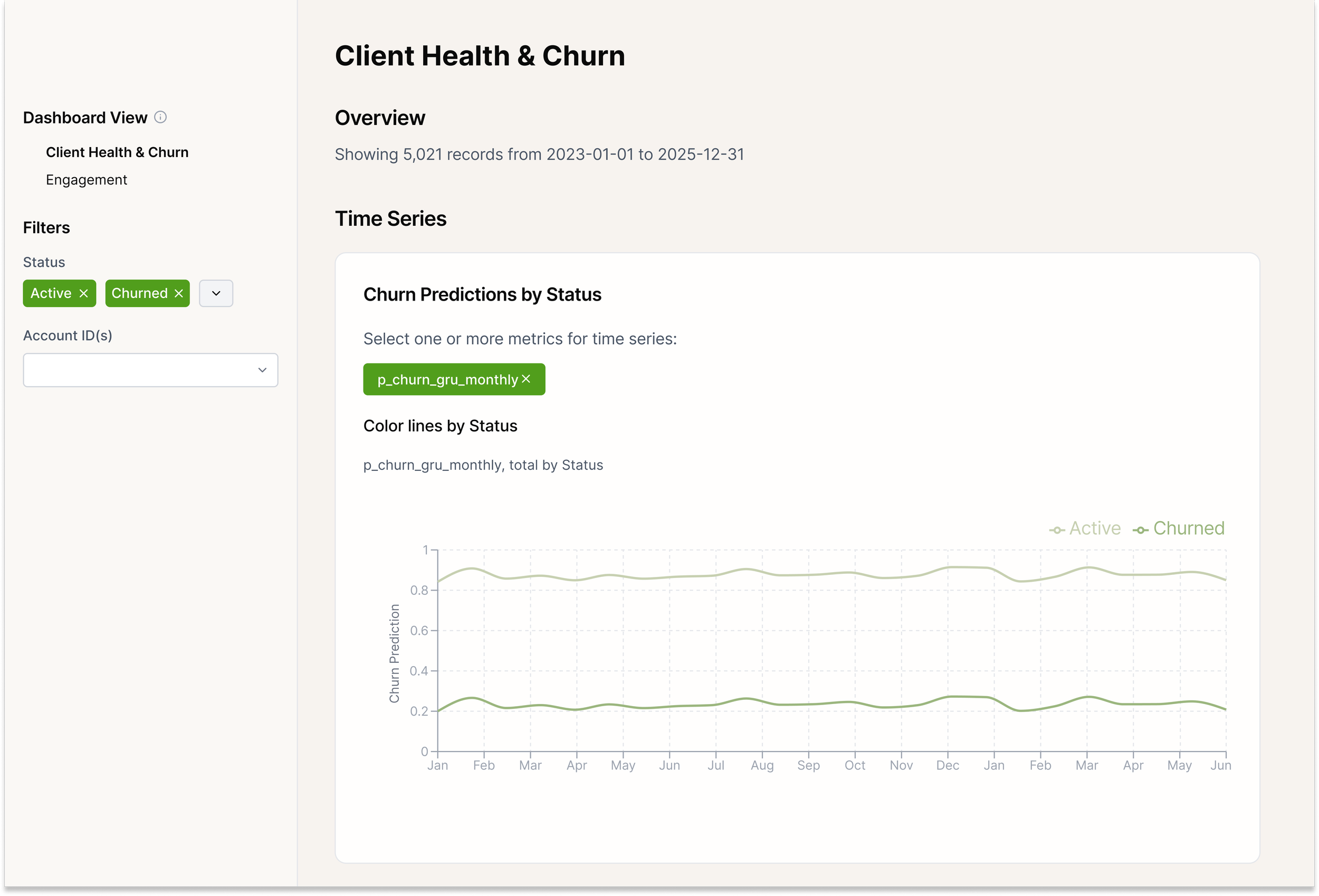
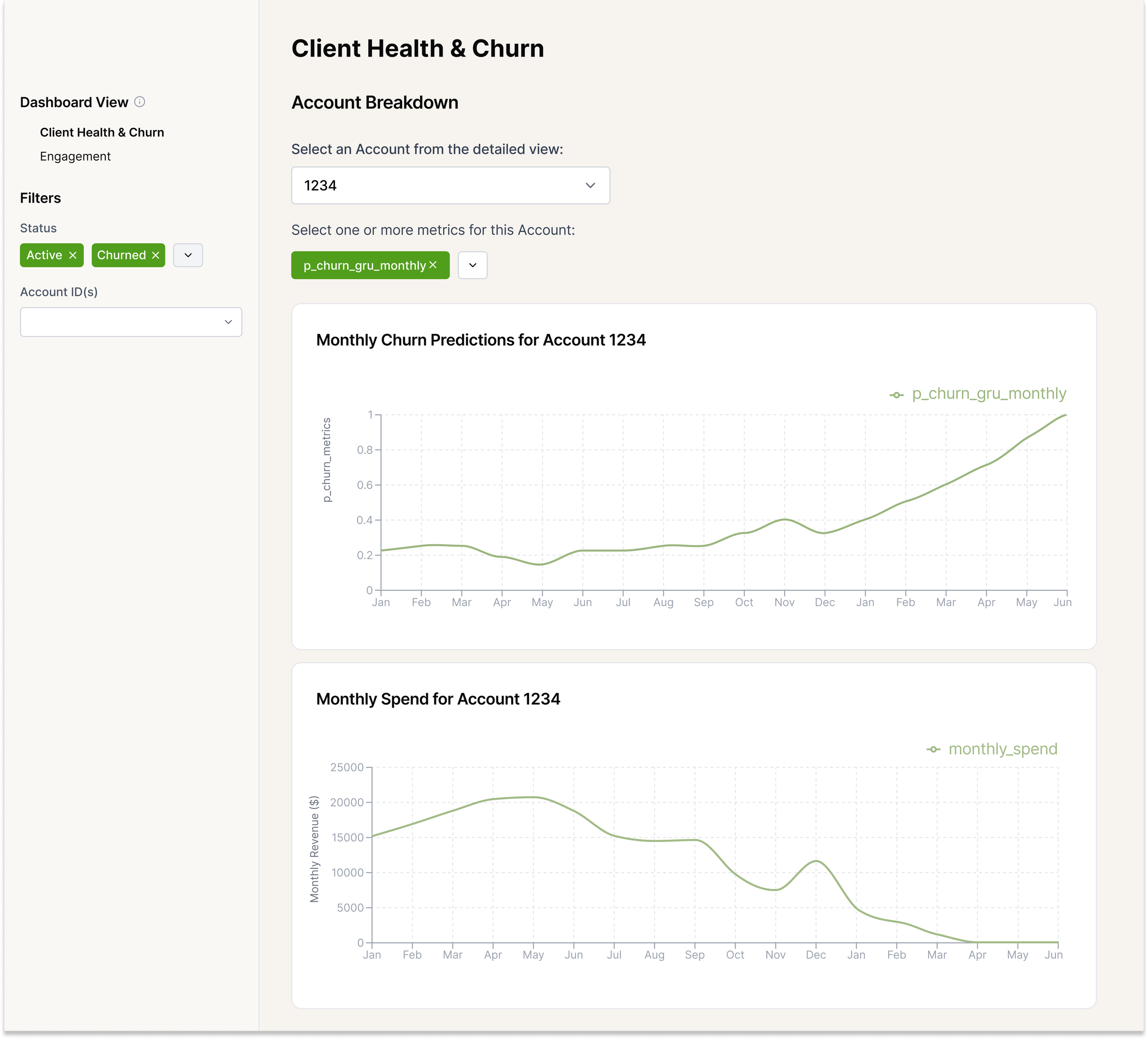
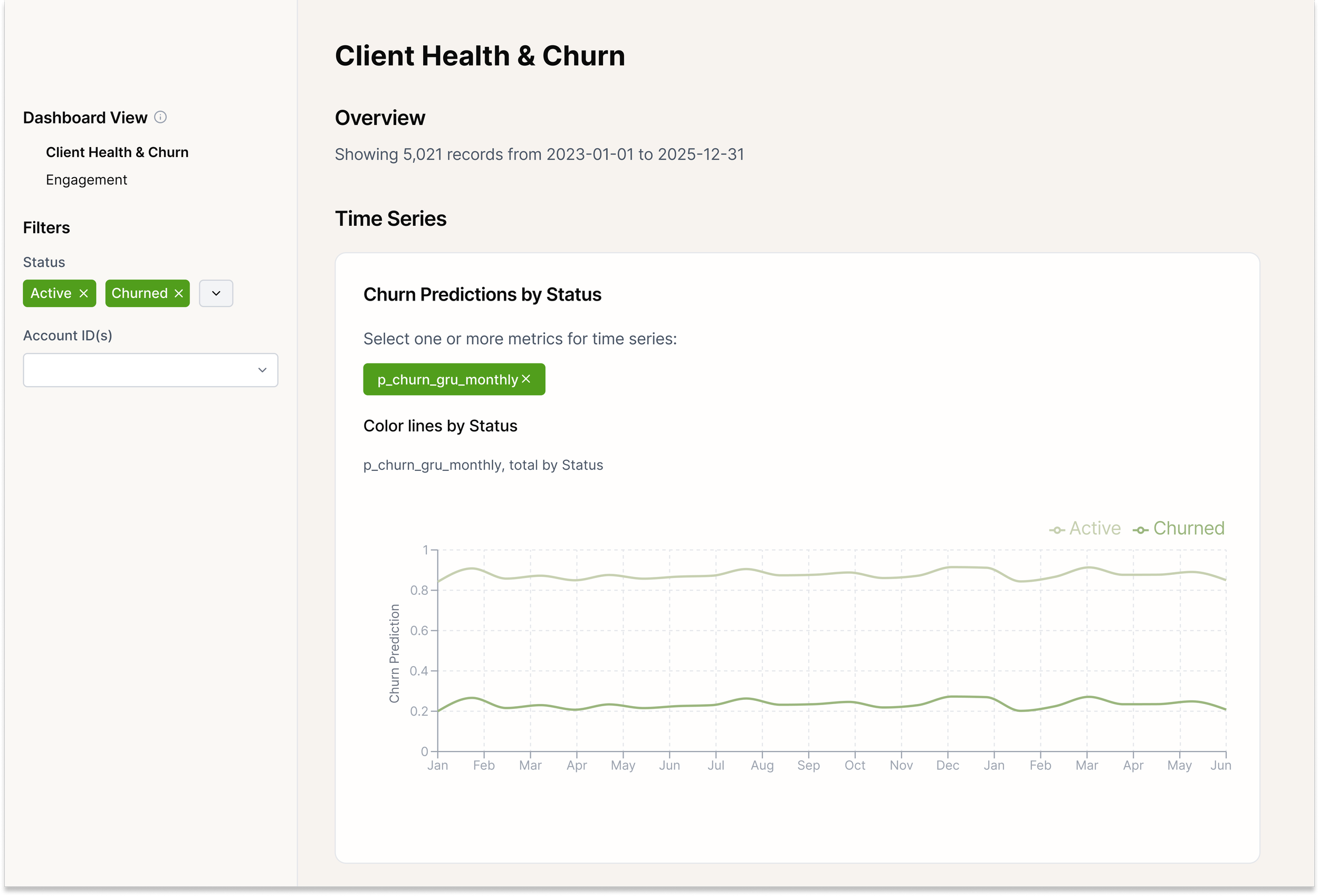
This project is a time-series churn prediction system built with a GRU (Gated Recurrent Unit) neural network in Python/PyTorch. It analyzes account-level behavioural data over time and outputs a per-period churn probability (p_churn_gru) for each account.
The model is designed to work with different reporting cadences (monthly, weekly, etc.), making it flexible for real business reporting cycles. It includes end-to-end steps for data prep, sequence modelling, training/validation, performance tracking (AUC, average precision, Brier score), and reproducible output artifacts.
The Problem

Traditional churn models often treat each customer snapshot independently, but churn is usually a progressive pattern over time. In this case, the challenge was to predict churn risk using panel data where each advertiser has a sequence of period-by-period metrics.
Key problems addressed:
Capturing temporal behaviour changes instead of static snapshots
Handling variable sequence lengths across advertisers
Training with partially labeled data (some periods have missing labels)
Producing actionable, period-level churn scores that can be used by retention and account teams
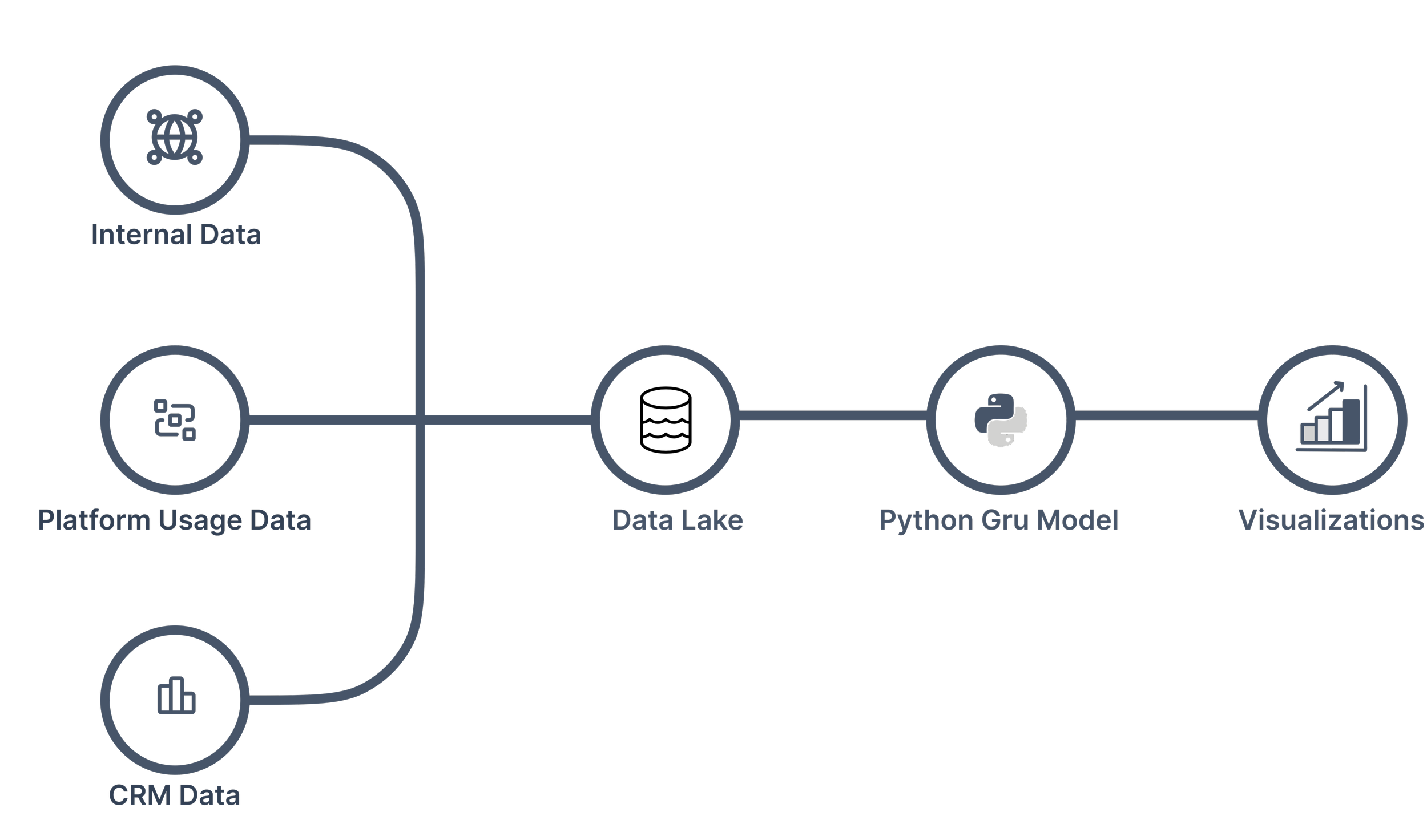
Approach
I built a sequence-learning pipeline centred on a GRU architecture:
Data engineering: Loaded account-period panel data, normalized timestamps to a chosen cadence, inferred numeric feature columns, and aligned labels from an external source where needed.
Sequence construction: Grouped data by account into variable-length sequences and used padded batching with masks so the model only learns from valid labeled time steps.
Model design: Implemented a GRU + dense prediction head to estimate churn probability at each time step.
Training strategy: Split train/validation at the advertiser level to avoid leakage, standardized features with StandardScaler, and trained with masked binary cross-entropy.
Evaluation + outputs: Tracked discrimination and calibration metrics (AUC, AP, Brier), saved model/scaler/config/history artifacts, and generated final scored outputs for downstream churn monitoring.
Results
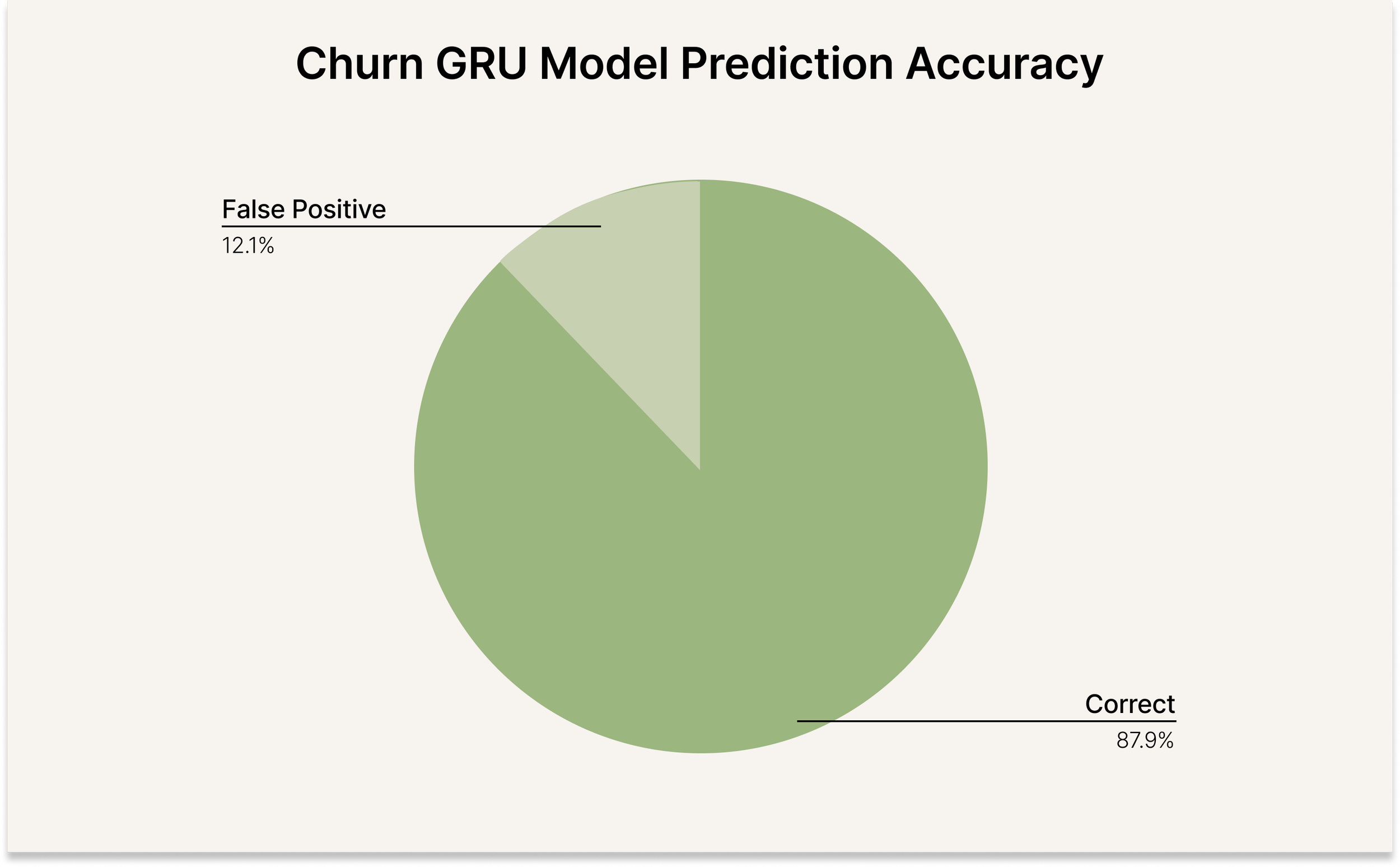
The GRU churn model produced a repeatable, production-ready scoring pipeline that generates per-period churn probabilities for each account and supports monthly (or weekly) monitoring.
By moving from static views to sequential modelling, the project improved the ability to detect early churn signals and prioritize high-risk accounts for retention outreach.
The final deliverables included not only predictions, but also full reproducibility assets (model weights, scaler parameters, config, and training history), making the solution easy to audit, retrain, and operationalize. Performance was tracked using AUC, Average Precision, and Brier Score to evaluate both ranking quality and probability calibration.